记录搭建 gitlab-ci 服务相关概念;
配置太多,很多不是很理解,仅做个记录,方便后期查阅;
Gitlab-ci
前置概念
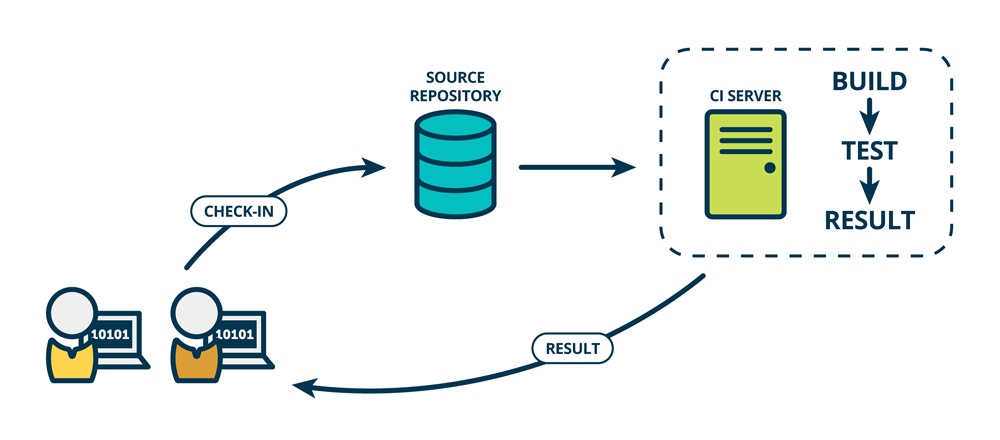
- 持续集成(Continuous Integration)
- 持续集成强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起
- 个人开发代码->构建、单元测试->向原有代码上集成
- 主要用来发现个人开发代码是否能主体代码上集成
- 持续交付(Continuous Delivery)
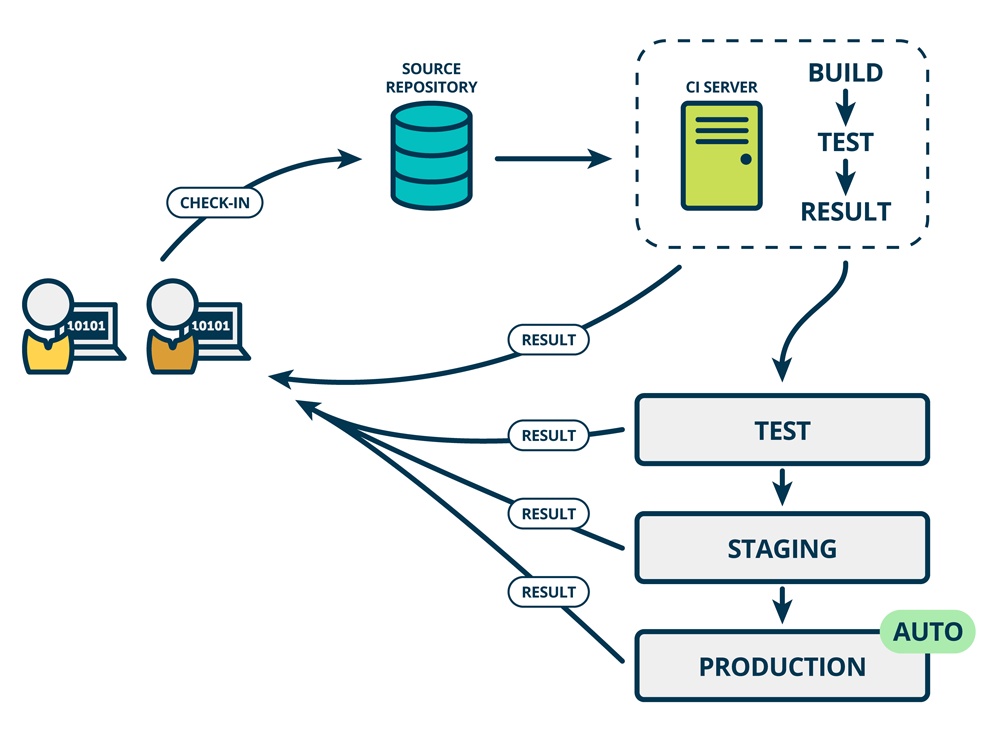
- 持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」(production-like environments)中。比如,我们完成单元测试后,可以把代码部署到连接数据库的 Staging 环境中更多的测试。如果代码没有问题,可以继续手动部署到生产环境中。
- 主要用来将持续集成后的成果进行更加拟真的测试
- 持续集成成果->拟真环境测试->手动部署到生产环境

- 持续部署(Continuous Deployment)
- 持续部署则是在持续交付的基础上,把部署到生产环境的过程自动化。
- 将手动部署过程进行自动化
- 手动部署到生产环境->自动部署到生产环境中
- DevOps
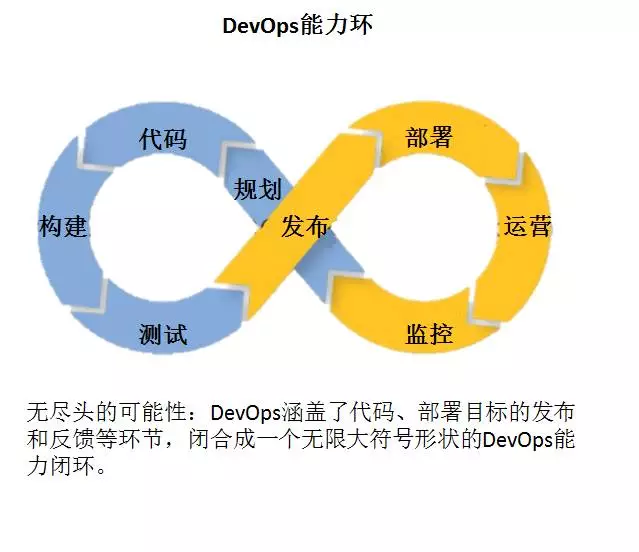
- DevOps 是一个概念,是 Development 和 Operations 的组合
- 突出重视软件开发人员和运维人员的沟通合作,通过自动化流程来使得软件构建、测试、发布更加快捷、频繁和可靠
- 它是基于 CI/CD 的一个完整的软件开发自动化流程
起步
- 基本步骤
- 仓库根目录添加
.gitlab-ci.yml文件并配置相关参数- 配置相关 job
- 具体配置及相关概念参照下面
- 配置项目启用
RunnerRunner负责相关 job 的执行GitLab和Runner之间通过API通信,所以Runner’s machine要能连接到Gitlab 服务Runner可分为为某一个项目服务的和为多个项目服务的,后者称为Shared Runner
- 每次
push将自动触发 CI 的工作流(pipeline)
- 仓库根目录添加
.gitlab-ci.yml配置
.gitlab-ci.yml是.yml格式文件,注意缩进,始终用空格代替 tab.gitlab-ci.yml主要定义了一些在不同 stage(阶段) 需要执行的 jobs- 每个
.gitlab-ci.yml文件可以定义无数个job,每个job都定义在.yml的顶层 - 每个
job至少一包含一个script字段 - 每个
job的执行是相互独立、互不干扰的 job不能重名,一些 gitlab 的关键字不能使用,如image、services、stages、types、before_script、after_script、variables、cache
1 | job1: |
- 每个
job可以有一些参数来定义 job 的行为
| Keyword | Required | Description |
|---|---|---|
| script | yes | Defines a shell script which is executed by Runner(定义要执行的脚本) |
| extends | no | Defines a configuration entry that this job is going to inherit from (定义此job将继承于哪个job) |
| image | no | Use docker image, covered in Using Docker Images (docker镜像) |
| services | no | Use docker services, covered in Using Docker Images (docker服务) |
| stage | no | Defines a job stage (default: test)(定义job所属的pipeline阶段,默认是test阶段) |
| type | no | Alias for stage (stage别名) |
| variables | no | Define job variables on a job level(定义在当前job执行时生效的变量) |
| only | no | Defines a list of git refs for which job is created(定义job执行范围及时机) |
| except | no | Defines a list of git refs for which job is not created(定义job执行范围及时机) |
| tags | no | Defines a list of tags which are used to select Runner(拥有制定Runner tag的runner才能执行此job) |
| allow_failure | no | Allow job to fail. Failed job doesn’t contribute to commit status(此job是否允许失败) |
| when | no | Define when to run job. Can be on_success, on_failure, always or manual (定义job什么时候能被执行,可以是on_success,on_failure,always或者manual) |
| dependencies | no | Define other jobs that a job depends on so that you can pass artifacts between them(定义了该job依赖哪一个job,如果设置该项,你可以通过artifacts设置) |
| artifacts | no | Define list of job artifacts(工件。。就是在依赖项之间传递的东西) |
| cache | no | Define list of files that should be cached between subsequent runs(定义需要被缓存的文件、文件夹列表) |
| before_script | no | Override a set of commands that are executed before job(在每个job执行前将执行的script) |
| after_script | no | Override a set of commands that are executed after job(在每个job执行后执行的script) |
| environment | no | Defines a name of environment to which deployment is done by this job(定义让job完成部署的环境名称) |
| coverage | no | Define code coverage settings for a given job(允许你设置代码覆盖率输出,其值从job的输出获取) |
| retry | no | Define when and how many times a job can be auto-retried in case of a failure(定义job失败后的自动重试次数) |
| parallel | no | Defines how many instances of a job should be run in parallel(最大可并行执行的job实例数) |
extends- 定义job继承行为
- 使用
include能够实现跨配置文件的job继承1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# 使用yml的隐藏key来创建隐藏job,通过添加点号来实现。隐藏job将不会被执行,但可以被继承
.tests:
script: rake test
stage: test
only:
refs:
- branches
rspec:
extends: .tests
script: rake rspec
only:
variables:
- $RSPEC
# 继承结果,后定义的将覆盖先定义的
rspec:
script: rake rspec
stage: test
only:
refs:
- branches
variables:
- $RSPEC
before_script、after_scriptbefore_script每个job执行前必须执行的scriptbefore_script和job的script享有同一执行环境(可访问到job中的变量)
after_script每个job执行后必须执行的scriptafter_script无法访问到job中的变量1
2
3
4
5
6
7
8
9
10
11
12# 全局
before_script:
- global before script
job:
# 局部,将覆盖全局
before_script:
- execute this instead of global before script
script:
- my command
after_script:
- execute this after my script
stages- 定义job所属阶段
- 可在全局中先定义所有阶段(stage)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25stages:
# 预定义需要按顺序执行的阶段
- build
- test
- deploy
job 1:
# job1属于build阶段
stage: build
script: make build dependencies
job 2:
# job2也属于build阶段
stage: build
script: make build artifacts
job 3:
# job3属于test阶段
stage: test
script: make test
job 4:
# job4属于deploy阶段
stage: deploy
script: make deploy
script- job唯一必填字段
- 指定此job需要执行的脚本,可是一个也可是多个
1
2
3
4
5
6
7
8
9job1:
# 指定一个脚本
script: "bundle exec rspec"
job2:
# 指定顺序执行的两个脚本
script:
- uname -a
- bundle exec rspec
only、expect- 指定此job的执行范围或时机,在哪个branch或者tag上执行,在何时触发
1
2
3
4
5
6
7
8job:
# use regexp
only:
- /^issue-.*$/
# use special keyword
except:
- branches
# 只会在issue-的ref上触发此任务,并派出了所有branche
- 指定此job的执行范围或时机,在哪个branch或者tag上执行,在何时触发
tags- 用来指定可以运行此job的
Runner,每个Runner在创建时可以指定一个Runner's tag1
2
3
4
5job:
# 拥有ruby、postgres标签的runner才能执行此job
tags:
- ruby
- postgres
- 用来指定可以运行此job的
allow_failure- 是否允许此job执行失败
- 正常情况,如果job执行失败,会中断后续stage的job执行
- 若为true,将不中断后续stage的job执行
- 是否允许此job执行失败
when- 标识当前job,在stage中某一job执行失败或所有job执行成功时才执行
关键字
on_success- 在前一stage中所有job都执行成功后再执行
on_failure- 在前一stage中有一个job执行失败时,就立即执行
always- 无论前一stage成功或失败都将执行此job
manual- 手动执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36stages:
- build
- cleanup_build
- test
- deploy
- cleanup
build_job:
stage: build
script:
- make build
cleanup_build_job:
stage: cleanup_build
script:
- cleanup build when failed
when: on_failure
test_job:
stage: test
script:
- make test
deploy_job:
stage: deploy
script:
- make deploy
when: manual
cleanup_job:
stage: cleanup
script:
- cleanup after jobs
when: always
# cleanup_build_job将只在build阶段失败时执行
# cleanup_job无论前面阶段是否执行成功都将执行
- 手动执行
environment- 是用于定义一个job部署到某个具名的环境
environment:on_stop、environment:action- on_stop指定在环境关闭时执行某个job
- action关键字和on_stop关键字相关,定义在job的environment中,用于响应关闭环境的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15review_app:
stage: deploy
script: make deploy-app
environment:
name: review
on_stop: stop_review_app
stop_review_app:
stage: deploy
script: make delete-app
when: manual
environment:
name: review
action: stop
# 我们建立了一个review_app并部署到review环境,并且我们在on_stop下同样定义了一个新的job名为stop_review_app。一旦review_app作业成功完成,ci将可以在手动操作的时候触发stop_review_app的任务,在这个例子中,我们使用when来达到手动触发停止review app的功能
artifactsartifacts被用于在job作业成功后将制定列表里的文件或文件夹附加到job上,传递给下一个job,如果要在两个job之间传递artifacts,你必须设置dependencies,传递文件/文件夹
1
2
3
4artifacts:
paths:
- binaries/
- .config传递git没有追踪的文件
1
2artifacts:
untracked: true只为打tags的行为创建artifacts
1
2
3
4
5
6
7
8
9
10
11
12
13
14default-job:
script:
- mvn test -U
except:
- tags
release-job:
script:
- mvn package -U
artifacts:
paths:
- target/*.war
only:
- tags创创建一个压缩包,命名为“job名_分支名”并包含为被git跟踪的文件
1
2
3
4job:
artifacts:
name: "${CI_JOB_NAME}_${CI_COMMIT_REF_NAME}"
untracked: true当失败时上传artifacts
1
2
3job:
artifacts:
when: on_failure
-设置artifacts一星期过期,默认artifacts会永远保存在gitlab中
1
2
3job:
artifacts:
expire_in: 1 weekcache- 定义在不同job间需要缓存的文件、文件夹(并不明白他和artifacts的区别)
dependenciesdependencies需要结合artifacts使用,只有定义了依赖关系的job才可以传递artifacts(怀疑中?)
coverage- coverage 允许你设置代码覆盖率输出,其值从job的输出获取
1
2
3job1:
script: rspec
coverage: '/Code coverage: \d+\.\d+/'
- coverage 允许你设置代码覆盖率输出,其值从job的输出获取
parallel- 最大可并行执行的job实例数
1
2
3test:
script: rspec
parallel: 5
- 最大可并行执行的job实例数
include- 导入其他配置文件
1
2
3
4
5include: 'https://gitlab.com/awesome-project/raw/master/.before-script-template.yml'
rspec:
script:
- bundle exec rspec
- 导入其他配置文件
variables- 定义变量
1
2
3
4
5
6
7# 全局变量
variables:
DATABASE_URL: "postgres://postgres@postgres/my_database"
job_name:
# 局部变量
variables: {}
- 定义变量
Git Strategy
- 你可以通过在全局变量设置位置或者job局部变量设置位置来设置GIT_STRATEGY用以获取应用最近更新的代码。
1
2
3
4
5
6
7
8
9
10
11# clone是最慢的选项,如果设置该值,每个job将会都克隆一遍仓库,确保项目工作空间总是原始的正确的。
variables:
GIT_STRATEGY: clone
# fetch是更快的操作选项,因为他重用了项目的工作空间(如果没有的话,会去clone), git clean用于撤销上一个job的任何操作,git fetch是用来重新获取上一个job运行到当前job产生的commit
variables:
GIT_STRATEGY: fetch
# none也同样重用了项目空间(但是他会跳过所有git操作,包括如果存在的gitlab runner的预克隆脚本)。其主要用于只是为了操作artifacts的job上(例如depoly部署行为)。此时Git仓库的数据可能是存在的,但它一定不是最新的。所以在设置了none的job里你应该依赖从cache或者artifacts来的数据,而不是仓库数据。
variables:
GIT_STRATEGY: none
- 你可以通过在全局变量设置位置或者job局部变量设置位置来设置GIT_STRATEGY用以获取应用最近更新的代码。
Git checkout
- 用来指定job执行时是否需要执行git checkout命令
1
2
3
4
5
6
7variables:
GIT_STRATEGY: clone
# 全局定义,执行job时无需checkout
GIT_CHECKOUT: "false"
script:
- git checkout master
- git merge $CI_BUILD_REF_NAME
- 用来指定job执行时是否需要执行git checkout命令
Shallow cloning
- 你可以通过GIT_DEPTH来设置抓取或者克隆深度。这将使得仓库进行浅克隆, 如果你的仓库有特别大量的commits或者仓库好久没更新了,该设置将显著的提高克隆速度。该参数会发送给git fetch和git clone操作(其实就相当于git fetch –depth=xxx, git clone –depth=xxx。但是由于git fetch和git clone是runner在执行job时帮你做的,所以需要此配置。)
1
2
3
4# 抓取或者克隆最新三条commits:
variables:
GIT_DEPTH: "3"
- 你可以通过GIT_DEPTH来设置抓取或者克隆深度。这将使得仓库进行浅克隆, 如果你的仓库有特别大量的commits或者仓库好久没更新了,该设置将显著的提高克隆速度。该参数会发送给git fetch和git clone操作(其实就相当于git fetch –depth=xxx, git clone –depth=xxx。但是由于git fetch和git clone是runner在执行job时帮你做的,所以需要此配置。)
隐藏job
- job名前添加点号即可,此job不被执行,但可以被继承
1
2
3.hidden_job:
script:
- run test
- job名前添加点号即可,此job不被执行,但可以被继承
Anchors
类似混入概念
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38.job_template: # Hidden key that defines an anchor named 'job_definition'
image: ruby:2.1
services:
- postgres
- redis
test1:
<<: # Merge the contents of the 'job_definition' alias
script:
- test1 project
test2:
<<: # Merge the contents of the 'job_definition' alias
script:
- test2 project
# 结果
.job_template:
image: ruby:2.1
services:
- postgres
- redis
test1:
image: ruby:2.1
services:
- postgres
- redis
script:
- test1 project
test2:
image: ruby:2.1
services:
- postgres
- redis
script:
- test2 project跳过job
- 如果你的commit信息包涵[ci skip]或者[skip ci],此次提交将不被job执行
总结
- script
- 定义具体脚本
- job
- 每个job可以执行一个或多个script
- 多个script按定义时顺序先后执行
- stage
- 每个阶段由不同job组成
- 每个job并行执行互不干扰
- 只有当前stage所有job都执行成功,才能进入下一阶段。一个job执行失败,标识此阶段fail
- pipeline
- 由多个阶段组成(build->test->deploy)
- Runner负责管理调配执行上述过程
参考
https://segmentfault.com/a/1190000011881435
https://segmentfault.com/a/1190000011890710#articleHeader31